UPDATE – 20181203:
or just use the microsoft driver as described on reddit – https://www.reddit.com/r/ChipCommunity/comments/5hndoj/setting_up_the_chip_under_win10_walkthrough/
Today I got my new CHIP (https://nextthing.co) dev board/mini pc and tryed to set it up, but as I found out thats quite tricky to do.
Regarding to the documentation the chip only needs to be connected to a pc with a micro USB cable and is automatically installed as serial device. After the installation the chip should be accessible via a COM-port with putty or any other program for serial communication.
So far so good, BUT … as I had to find out, the driver didn’t got installed and so it wasn’t accessible …
By default Windows should identify the device automatically and install the CDC Composite Gadget driver out of the box. But in my case it didn’t work.
It seems that the identfier canged from A4A7 to A4AA:
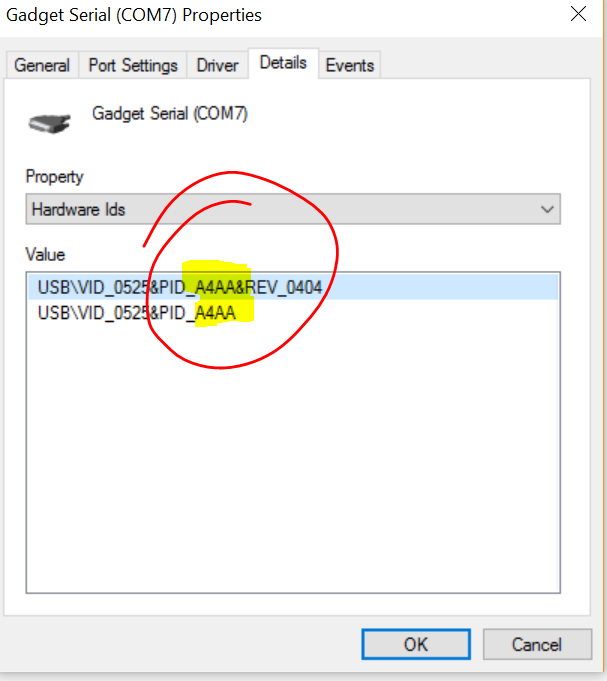
After some some googleing I found a driver on kernel.org which nearly worked.
https://www.kernel.org/doc/Documentation/usb/linux-cdc-acm.inf
But it would have been too easy if it worked out of the box. So I had to adapt the *.inf-file to match my HW-ID.
Change the follwoing lines
[pastacode lang=”python” manual=”%5BDeviceList%5D%0A%25DESCRIPTION%25%3DDriverInstall%2C%20USB%5CVID_0525%26PID_A4A7%2C%20USB%5CVID_1D6B%26PID_0104%26MI_02%2C%20USB%5CVID_1D6B%26PID_0106%26MI_00%0A%0A%5BDeviceList.NTamd64%5D%0A%25DESCRIPTION%25%3DDriverInstall%2C%20USB%5CVID_0525%26PID_A4A7%2C%20USB%5CVID_1D6B%26PID_0104%26MI_02%2C%20USB%5CVID_1D6B%26PID_0106%26MI_00%0A” message=”” highlight=”” provider=”manual”/]
to
[pastacode lang=”python” manual=”%5BDeviceList%5D%0A%25DESCRIPTION%25%3DDriverInstall%2C%20USB%5CVID_0525%26PID_A4AA%2C%20USB%5CVID_1D6B%26PID_0104%26MI_02%2C%20USB%5CVID_1D6B%26PID_0106%26MI_00%0A%0A%5BDeviceList.NTamd64%5D%0A%25DESCRIPTION%25%3DDriverInstall%2C%20USB%5CVID_0525%26PID_A4AA%2C%20USB%5CVID_1D6B%26PID_0104%26MI_02%2C%20USB%5CVID_1D6B%26PID_0106%26MI_00%0A” message=”” highlight=”” provider=”manual”/]
In short: replace A4A7 with A4AA 😉
Afterwards the driver could be installed and the chip should work (as long as you do not have Windows 10).
If you try to install the driver on a Windows 10 machine, Windows will complain about the unsigned driver and will not install the driver.
To get it work on Windows 10, the OS needs to be rebooted in option mode:
shutdown.exe /r /o /f /t 00
When Windows starts up again the driver signature check could be disabled for this start and after the system is up again it’s possible to install the driver.
Continue reading Next Thing – C.H.I.P – Driver cant be installed →